Construire un agent DialogFlow performant, partie I
Dans le monde des chatbots, deux conceptions s’affrontent avec un impact fort sur l’expérience utilisateur : NLU ou non ?
Si le NLU peut créer une expérience conversationnelle unique pour les utilisateurs, sa mauvaise implémentation peut au contraire générer une expérience vraiment déceptive.
Chez Coddity nous sommes spécialisés sur la plateforme de chatbot nocode Dialogflow de Google, et autour de celle-ci nous allons vous présenter en 2 billets de blog :
- Comment construire et optimiser un NLU implémenté sur Dialogflow ? (sujet de cette partie I)
- Comment créer un dataset pour un bot fictif ? (partie II à venir)
NLU ?
Le NLU, pour Natural Language Understanding ou compréhension du langage naturel, permet de comprendre une intention utilisateur automatiquement à partir de phrases saisies. Cette méthode est un pan de recherche en IA / Data Science.
Un bot peut être construit sans NLU, c’est-à-dire que celui-ci présente une série de choix à l’utilisateur pour le guider et lui apporter les réponses nécessaires : une sorte de serveur vocal interactif numérique sans vocal (quoique, nous pourrons revenir dans un autre article sur les bots vocaux).
Cependant, si cette conception fonctionne très bien pour des bots très spécialisés ou à faible exposition, l’ajout d’une détection NLU permet un transformer une expérience de “clic-bouton” assez austère en vraie conversation interactive.
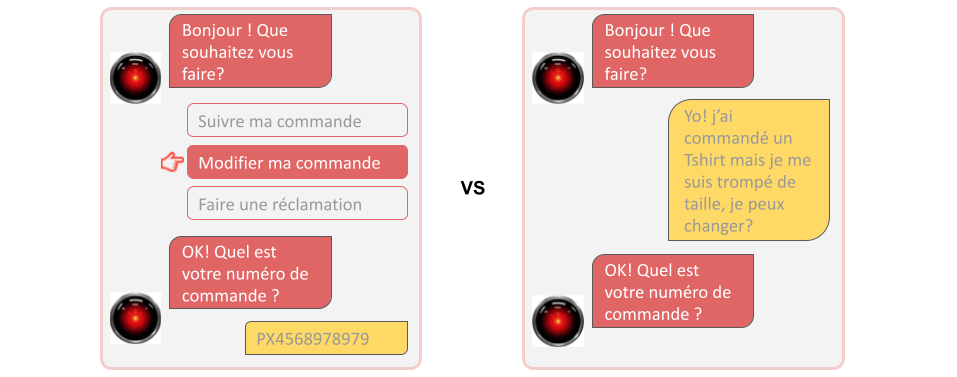
Mais attention !
Le NLU n’est pas un outil magique qui comprend tout, nativement, dès l’implémention. La performance et la qualité de sa détection dépendent avant tout de sa conception et de son entraînement, que nous allons détailler dans la suite de cet article pour la plateforme Dialogflow.
Dans cet article, nous allons vous présenter les bonnes pratiques à suivre pour construire un agent Dialogflow performant.
Dialogflow ?
Dialogflow est le moteur de NLU de Google et permet de construire de A à Z des chatbots. Son interface modulaire est très complète et s’adapte aux besoins : utilisation uniquement du NLU via des API, construction d’un bot complet avec 0 ligne de code, intégration avec des messagerie ou CRM, etc.
La plateforme est très bien intégrée à Google Cloud Platform, ce qui ajoute une modularité supplémentaire et permet en complément l’utilisation d’outils d’exploitation.
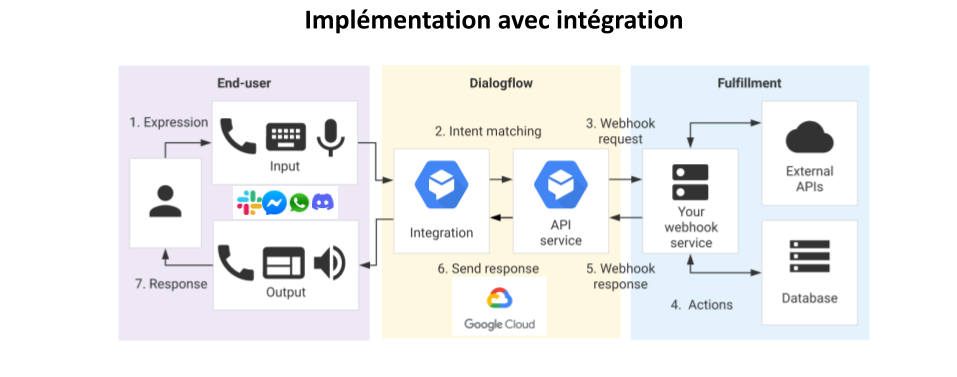
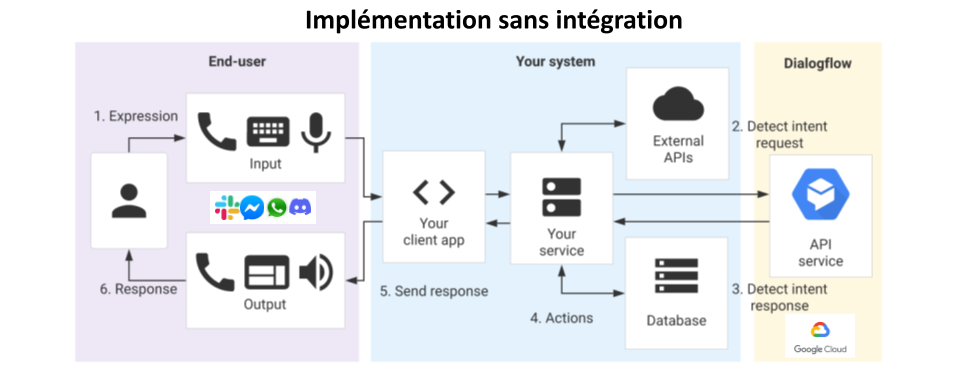
ATTENTION, cet article n’a pas vocation à être un tutoriel vous permettant de constuire un bot de bout en bout, nous allons nous concentrer sur comment construire une détection d’intention performante sur Dialogflow.
Dataset, détections d’intentions et entités
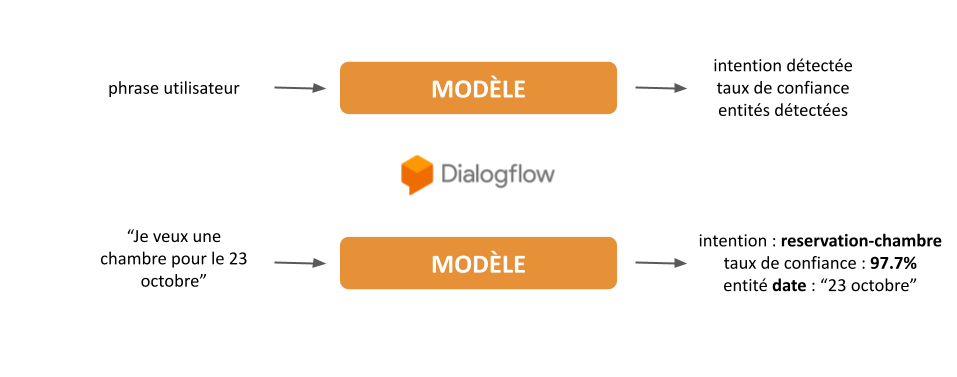
En simplifiant les choses, le NLU est un modèle qui reçoit en entrée une phrase écrite en langage naturel et en identifie le sens selon une probabilité plus ou moins forte.
Pour notre cas de chatbot, le NLU va, à partir d’une phrase saisie par un utilisateur, identifier ce que l’on appelle une intention, c’est-à-dire la volonté de l’utilisateur.
Vous imaginez bien qu’un modèle de NLU / IA qui comprendrait toutes les intentions humaines n’existe pas (du moins pas encore), ceux-ci sont forcément spécialisés et créés pour un champ d’intentions spécifiques.
Pour créer un modèle de NLU spécialisé, on va lui injecter une série de phrases d’exemples par intention, c’est ce qu’on appelle l’entraînement. L’ensemble des intentions et des phrases d’entraînement correspondantes sera appelée dataset.
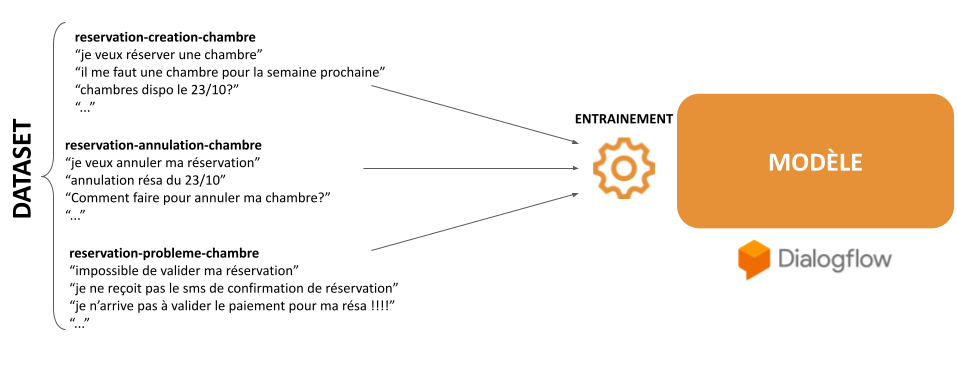
Outre la détection d’intention, les modèles de NLU permettent d’extraire sur les phrases client des entités qui sont des paramètres liés à une intention, comme par exemple une date pour une réservation de chambre ou une référence pour le suivi d’un dossier ou commande.
D’autres fonctionnalités peuvent être intégrées au modèle comme par exemple l’analyse de sentiment, que nous traiterons dans un autre article.
La plateforme Dialogflow permet la création d’un modèle de NLU, qui se nomme agent sur la plateforme. La création des intentions et des entités est très facile grâce à une UI claire et intuitive.
Concevoir un dataset
ETAPE 1 : la spécialisation
Cette étape est primordiale, il s’agit de découper le périmètre métier selon des intentions qui seront celles utilisées par nos utilisateurs, c’est-à-dire de spécialiser notre dataset.
Que votre bot va-t-il offrir comme possibilité ? Que vos utilisateurs vont-ils lui demander ?
Segmenter les périmètres métier
La première chose à faire sera de segmenter les périmètres métiers, c’est à dire les champs d’actions du bot, comme par exemple :
- des actions d’administration de compte ;
- des actions de gestion de commande ;
- des actions de gestion de livraison ;
- des actions de gestion de rendez-vous.
Identifier les intentions des utilisateurs
Il faut maintenant identifier les intentions potentielles des utilisateurs en les spécialisant au maximum. Si l’on prend comme exemple le périmètre métier de la gestion de livraisons, nous pouvons identifier les intentions ci-dessous :
- obtenir le statut de sa livraison ;
- modifier une adresse de livraison ;
- reporter un problème dans la qualité de la livraison ;
- reporter un problème dans la complétude de la livraison.
Attention à ne pas regrouper dans une intention plusieurs volontés de l’utilisateur ! Par exemple, ne pas créer une intention gestion des commandes qui va contenir la création, la modification et l’annulation de commande, qui sont trois volontés différentes.
Identifier les entités
Les entités vont nous permettre de capter des informations depuis les phrases utilisateur. Les entités sont spécifiques à certaines intentions mais peuvent être utilisées par plusieurs intentions.
Par exemple, imaginons que vous avez une entité “spécialité-medicale”. Celle-ci pourrait être utilisée pour caractériser :
- une réservation de rendez-vous avec un médecin (“je veux un rendez avec un pneumologue”) avec une intention “rdv-creation” ;
- une demande d’information relative à une spécialité médicale (“A quoi sert un pneumologue”) avec une intention “specialites-info”.
Dialogflow offre un certain nombre d’entités automatiques (comme la récupération de dates, d’adresses ou numéros de téléphone) et des entités “custom” propres au dataset que vous pouvez créer : un numéro de commande ou de facture, un nom de service métier ou d’option, etc.
Outre l’utilisation a posteriori dans vos scénarios des valeurs remontées par les entités, celles-ci aident le modèle à identifier les intentions et contribue à améliorer la détection. Par exemple, le modèle identifiera :
- plus facilement “rdv-creation” avec une entité “ville” ou “date” (“je veux un rendez-vous en octobre à Paris avec un pneumologue”) ;
- qu’une demande d’information sur son compte personnel via une intention “admin-info-compte” qui ne devrait pas contenir de date a priori.
Règles de nommage
Pensez à correctement nommer vos intentions, en suivant un pattern permettant d’en comprendre facilement le sens. Nous utilisons par exemple celui-ci : perimetre_metier-action-domaine comme par exemple : administration-info-compte ou commande-obtenir-numero.
ETAPE 2 : l’homogénéité
En data science, il existe une règle évidente à bien comprendre : les données qui servent à l’entraînement du modèle doivent être homogènes aux données de production : dans notre cas, les phrases d’entraînement des intentions doivent être proches des phrases des utilisateurs du bot.
Partant de ce principe, la création du dataset peut être problématique. Dispose-t-on de phrases d’utilisateurs ? Si oui, possède-t-on suffisamment de données et de bonne qualité ?
Si votre bot vient en complément d’un canal de chat (avec un service client par exemple), les premières phrases des utilisateurs au lancement du chat sont un bon point de départ pour la création de votre dataset. Vous devrez alors annoter ces phrases, c’est-à-dire les associer aux intentions que vous avez identifiées.
Si cependant vous ne disposez pas de telles données, vous allez devoir créer, imaginer, pour chacune des intentions, des phrases d’utilisateurs. Cela peut poser un problème si nous gardons un vocabulaire très “métier” : nos utilisateurs ne connaissent ni n’utilisent certainement pas NOTRE langage technique (acronymes propres à une organisation, etc.).
Chez Coddity, nous utilisons parfois des algorithmes permettant de créer automatiquement des variations de phrases à partir d’une seule et même phrase, ce qui nous permet de construire un dataset de départ rapidement.
Styles d’écriture et orthographe
A ce stade, une nouvelle contrainte apparaît : il existe de fortes différences de syntaxe et d’orthographe entre les phrases d’entraînement et les phrases d’utilisateurs réels.
Vos utilisateurs font des fautes, et beaucoup plus que vous ne pourriez imaginer ! Votre dataset devra donc prendre en compte cet aspect, au risque d’avoir un modèle entraîné avec des données éloignées de la production.
A noter que Dialogflow permet d’ajouter un redressement orthographique en entrée des phrases envoyées par l’utilisateur, mais même s’il permet de corriger des erreurs, il n’est pas parfait et peut en laisser passer. Ce correcteur est un très bon filet de sécurité mais ne doit pas constituer votre seule stratégie quant au problème de variations d’orthographe.
A ce sujet, chez Coddity nous avons fait une expérience sur un dataset que nous avons entièrement corrigé à la main. Notre mesure de performance (recall) avec le correcteur orthographique activé à montré une perte de 3 points par rapport à l’utilisation du modèle entraîné avec le dataset initial.
Votre modèle doit donc prendre en compte nativement le fait que vos utilisateurs font des fautes en intégrant dans son dataset d’entraînement des styles et formes d’expression différentes. Son objectif est de comprendre l’utilisateur, même s’il faut pour cela faire fi des règles parfois élémentaires de la langue utilisée (et somme toute, n’est-ce pas là l’idée de la communication ?).
ETAPE 3 : la vie du bot
Maintenant que vous avez un dataset performant, vous pouvez le laisser vivre sa vie sans vous en soucier… Evidemment, c’est un #hashtag joke.
Observer votre modèle en production va vous apprendre beaucoup de choses :
- il vous permettra de mesurer la performance de votre modèle (nous y reviendrons dans un prochain article) ;
- les phrases utilisées par vos utilisateurs vous serviront à réentraîner votre modèle en corrigeant le biais “métier” décrit à l’étape 2 ;
- vous verrez apparaître des intentions que vous n’aviez absolument pas prévu dans votre découpage métier initial, réalisé à l’étape 1.
Ce dernier point va vous permettre d’apporter une vraie valeur à vos utilisateurs, voire même de détecter des anomalies sur vos process !
Versionning
Dialogflow dispose d’un système de versionning vous permettant de créer différentes versions de votre agent, déployable sur des environnements customs. Vous pouvez donc modifier si vous le souhaitez le découpage de vos intentions, le déployer sur un environnement différent et faire de l’A/B testing sur des sources différentes !

La suite
Vous avez maintenant la méthodologie pour créer un dataset performant ! Nous appliquerons dans un prochain article ce que nous avons vu ci-dessus avec la création du dataset de leobot, un bot municipal.